正規表現で検索がめっちゃ楽になる
こんにちは、ノムノムです。
今回は、正規表現について説明しようと思います。
その理由はですね。
私が開発したファイル名、フォルダ名一括変更ツール「ReFaD」でファイル名変更ルール作成時に正規表現を使用できるようにしたのでぜひマスターして欲しいと思いました。

とは言ってもそれほど難しく考えることもないと思います。
正規表現とは
正規表現とは、いろんな文字列を一つの文字列で表現する方法の一つです。
例えば、以下のようなフォルダがあるとします。
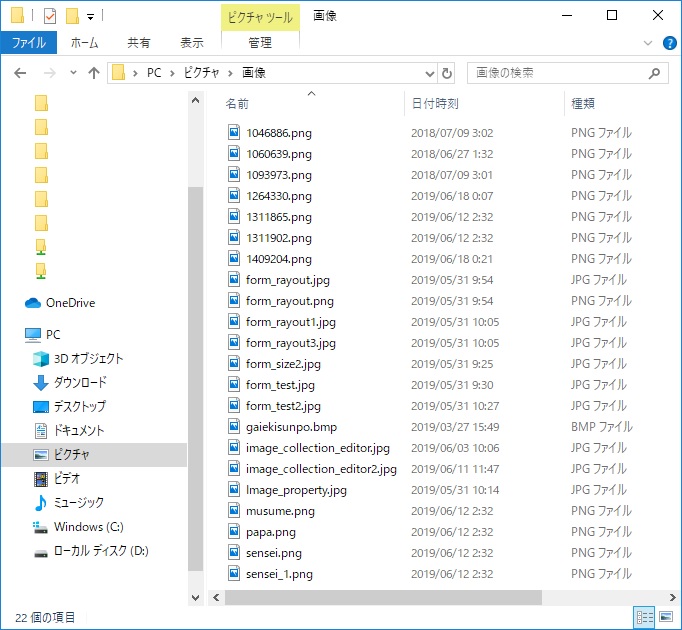
この中から「jpgファイル」だけ取り出したい。とか「p」が先頭にあるファイルだけ取り出したいなど
様々な条件を正規表現で表すことができ、それを検索や置換などに使用することができるのです。
正規表現のルール
正規表現で表現すると言っても基本的にはただの文字列です。そう身構えることのものでもありません。
正規表現で使用する特殊文字(メタ文字)があります。この特殊文字が出てくるところが、正規表現の部分です。
主な特殊文字は、「. ^ $ [ ] * + ? | ( )」です。
あいまいな表現をする特殊文字「.」
どんな文字でも1文字対象にすることができる特殊文字「.」です。
例
正規表現:ai..o
意味:aiとoの間になんでもいいので2文字ある場合
| aiueo | OK |
| aixuo | OK |
| aio | NG |
| aiuero | NG |
繰り返しを表現する特殊文字「*」「+」「?」
一つ前の文字を対象に繰り返しを行う特殊文字です。
- 「*」:一つ前の文字が0回以上繰り返される場合
- 「+」: 一つ前の文字が1以上繰り返される場合
- 「?」:一つ前の文字が0回または1回の場合
一つ前の文字が対象なので特殊文字「.」を置けばどんな文字でもできるということです。
例
| 正規表現 | 文字列 | 判定 |
| a*o | aiueo | OK 「o」が対象になります。 |
| a.*o | aiueo | OK 「aiueo」が対象になります。 |
| a.*o | ao | OK 「ao」が対象になります。 |
| .* | aiueo | OK 「aiueo」が対象になります。 |
| a+o | aiueo | NG |
| a+o | aaaaaao | OK 「 aaaaaao 」が対象になります。 |
| a.+o | aiueo | OK 「aiueo」が対象になります。 |
| a.+o | ao | NG |
| ai?ueo | aiueo | OK 「aiueo」が対象になります。 |
| ai?ueo | aueo | OK 「aueo」が対象になります。 |
| a.?ueo | akueo | OK 「akueo」が対象になります。 |
先頭を意味する特殊文字「^」末尾を意味する特殊文字「$」
文字列の先頭から表現したい場合「^」を使い、文字列の末尾を表現したい場合は「$」を使います。
例
| 正規表現 | 文字列 | 判定 |
| ^aiueo | aiueo | OK |
| ^aiueo | sdaiueo | NG |
| aiueo$ | sdaiueo | OK |
| aiueo$ | aiueoka | NG |
範囲を表す特殊文字「[]」
いろいろな範囲を使いたい場合「[]」を使用します。
- abcのどれかを指定する場合[abc]
- 0~9の範囲を指定する場合 [0-9]
- a~zの範囲を指定する場合[a-z]
- A~Zの範囲を指定する場合[A-Z]
例
| 正規表現 | 文字列 | 判定 |
| a[iue]o | aiueo | NG 一文字しか対応ではない |
| a[iue]o | auo | OK |
| a[iue]*o | aiueo | OK |
| a[iue][iue][iue]o | aiueo | OK |
| a[a-z]o | aiueo | NG |
| a[a-z]*o | aiueo | OK |
| [0-9]*.jpg | 0001.jpg | OK |
| [0-9]*.jpg | 0001jpg.png | OK 「0001jpg」が引っ掛かります。 |
複数文字に対応したい場合は、*を後に付けると便利です。
いすれかの文字列を表す特殊文字「|」
文字列のいずれかを指定する特殊文字です。
文字列1|文字列2|文字列3
のように記載します。
例
| 正規表現 | 文字列 | 判定 |
| わたし|僕|俺 | 俺 | OK |
| わたし|僕|俺 | あなた | NG |
グループを表す特殊文字「()」
カッコで囲むことでその中を1つの文字としてあらわすことができます。
例
| 正規表現 | 文字列 | 判定 |
| (わたし|僕|俺)は元気です。 | わたしは元気です。 | OK |
| (わたし|僕|俺)は元気です。 | あなたは元気です。 | NG |
| (わたし|ぼく|おれ)*は元気です。 | おれわたしぼくおれは元気です。 | OK |
特殊文字を検索したい場合「\」
特殊文字を判定に使いたい場合は、特殊文字の前に「\」を置きます。
例
| 正規表現 | 文字列 | 判定 |
| \[正規表現\] | [正規表現] | OK |
| \[正規表現\] | 正規表現 | NG |
| .*\.jpg | IMG0120.jpg | OK |
| .*\.jpg | IMG0120jpg.png | NG |
正規表現で使われる記号
正規表現ではいろいろな文字種を「\」を使って表現できます。
通常の文字入力では入力できない文字も検索することができます。
以下にそのリストを表示します。
| 文字 | 説明 |
| \t | タブ |
| \r | キャリッジリターン |
| \n | ラインフィード |
| \r\n | 改行(キャリッジリターン+ラインフィード) |
| \w | [0-9A-Za-z_]と同じ |
| \W | [0-9A-Za-z_] 以外の文字 |
| \s | 空白 |
| \S | 空白以外の文字 |
あいまい検索をするには?
ここまで説明してきたのでVBにはあいまい検索を行うためにLike演算子というのがあります。ですがC#ではそれがありません。
それを正規表現を使って判定します。
サンプル
/// <summary>
/// あいまい検索
/// </summary>
/// <param name="buff"></param>
/// <param name="find"></param>
/// <returns></returns>
private bool IsMatchFuzzySearch(string buff, string find)
{
//正規表現を設定
string pattern = "^" + find + "$";
return System.Text.RegularExpressions.Regex.IsMatch(buff, pattern);
}正規表現の便利な使い方
正規表現はここまでやってきたものを組み合わせて使用するのです。
そのため、一見複雑そうに見えても単純なものが集まって難しそうに見えてるだけですね。
せっかくなので使える正規表現をやっていこうと思います。
ファイル名に禁止文字が入っているか確認する
ファイル名に禁止文字が入っているかどうかをチェックするためのロジックは、正規表現を使うと簡単に行うことができます。
それはこれです。
[\\x00-\\x1f<>:\"/\\\\|?*]|^(CON|PRN|AUX|NUL|COM[0-9]|LPT[0-9]|CLOCK\\$)(\\.|$)|[\\. ]$こまかく説明すると終わらなそうなのでざっくりと説明します。
まず「|」が目につきます。
これを分解すると
- [\x00-\x1f<>:\"/\\|?*]
- ^(CON|PRN|AUX|NUL|COM[0-9]|LPT[0-9]|CLOCK\$)(\.|$)
- 「\. ]$
に別れます。
これらにHitしてしまうとファイルやフォルダに使えない不正文字が入っているということになります。
サンプル
/// <summary>
/// ファイル禁止文字の判定
/// </summary>
/// <param name="file_name">ファイル名</param>
/// <returns>true:禁止文字無し false:禁止文字あり</returns>
private bool IsFileNameCheck(string file_name)
{
//正規表現を設定
string pattern = "[\\x00-\\x1f<>:\"/\\\\|?*]|^(CON|PRN|AUX|NUL|COM[0-9]|LPT[0-9]|CLOCK\\$)(\\.|$)|[\\. ]$";
//ヒットしたら禁止文字が入っているという事なので先頭に「!」をつけて反転させる
return !System.Text.RegularExpressions.Regex.IsMatch(file_name, pattern);
}URLが正しいか確認する
URLが正しいかどうかを判断するには以下の正規表現が利用できます。
https?://[\w/:%#\$&\?()~.=+-]+ただし、これは先頭がhttp~で始まるものだけなのでftp~などは使えません。
サンプル
/// <summary>
/// URLが正しいか判断する
/// </summary>
/// <param name="url">URL</param>
/// <returns>true:正しいURL false:不正URL</returns>
private bool IsURLCheck(string url)
{
//正規表現を設定
string pattern = "https?://[\w/:%#\$&\?()~.=+-]+";
//ヒットしたら正しいURL
return System.Text.RegularExpressions.Regex.IsMatch(url, pattern);
}文字列置換をする際に、置換前の文字列を一部使いたい
文字列置換を行う際以下のような置換前の文字を残したいと思うことはないでしょうか?
- photo001date20190704.jpg → IMG001_20190704.jpg
- photo002date20190704.jpg → IMG002_20190704.jpg
- photo003date20190704.jpg → IMG003_20190704.jpg
- photo004date20190704.jpg → IMG004_20190704.jpg
これも正規表現を使えば一回で変換可能です。
実はグループ「()」で囲ったものは置換時に「$数字」で呼び出せるのです。
$は先頭のグループから$1, $2と続いていきます。
例えば上記の例で言えば以下のようになります。
| 検索文字 | 置換文字 | 結果 |
|---|---|---|
| photo([0-9]*)date([0-9]*)\.jpg | IMG$1_$2.jpg | photo001date20190704.jpg → IMG001_20190704.jpg photo002date20190704.jpg → IMG002_20190704.jpg photo003date20190704.jpg → IMG003_20190704.jpg photo004date20190704.jpg → IMG004_20190704.jpg |
サンプル
それではC#でどうやるか見てみましょう
/// <summary>
/// 置換ボタンをクリック
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void btnReplace_Click(object sender, EventArgs e)
{
StringBuilder result = new StringBuilder();
this.txtResult.Text = "";
//1行ずつ取得する
foreach(string line in this.txtBuff.Lines)
{
//結果に追加
result.AppendLine(ReplaceRegEx(line, this.txtFind.Text, this.txtRep.Text));
}
//結果を表示
this.txtResult.Text = result.ToString();
}
/// <summary>
/// 正規表現で置換処理を行う
/// </summary>
/// <param name="input">入力文字</param>
/// <param name="find">正規表現検索文字</param>
/// <param name="rep">置換文字</param>
/// <returns></returns>
private string ReplaceRegEx(string input, string find, string rep)
{
//検索対象がない場合、置換を行わない
if (System.Text.RegularExpressions.Regex.IsMatch(input, find) == false)
{
return "";
}
//置換処理
return System.Text.RegularExpressions.Regex.Replace(input, find, rep);
}
実行してみる
実際に動かしてみました。どうでしょう。
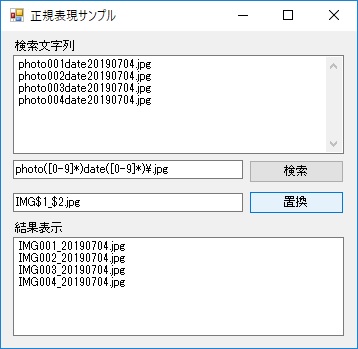
大丈夫そうですね。
まとめ
いかがでしたでしょうか?正規表現は使い慣れるといろんな検索ができてとても便利です。
ReFaDでも使っています。正規表現を使ると文字列のチェックなどは効率的に行うことができます。
これを機会にぜひ習得してみてはいかがでしょう?
ここまで読んで頂いてありがとございます。