【C#】ホームページ上の画像を一括でダウンロードしちゃうツール&ソース公開
こんにちは、ノムノムです。
今回は、ホームページ上の画像ファイルだけを取得する方法を解説します。
ただし、ホームページから画像を一度に取得できるからといって違法ダウンロードはダメですよ。
当サイトはツールによる不具合、不利益に関して一切の責任を負いません。
ダウンロード
ImgDownLoader
ツールの使い方
今回のツールは作り込むことではありませんのでとても簡素にしています。
バカチョンプログラム、通称チョンプロと呼ばれるレベルです。
いいんです。目的さえ達成できればチョンプロでも!
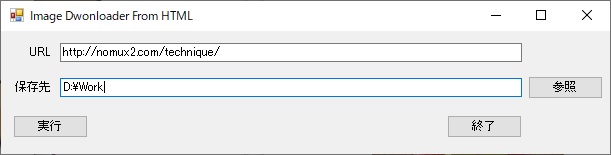
使い方は簡単、ダウンロードしたいサイトのURLを入れて保存するフォルダを指定して実行するだけ!
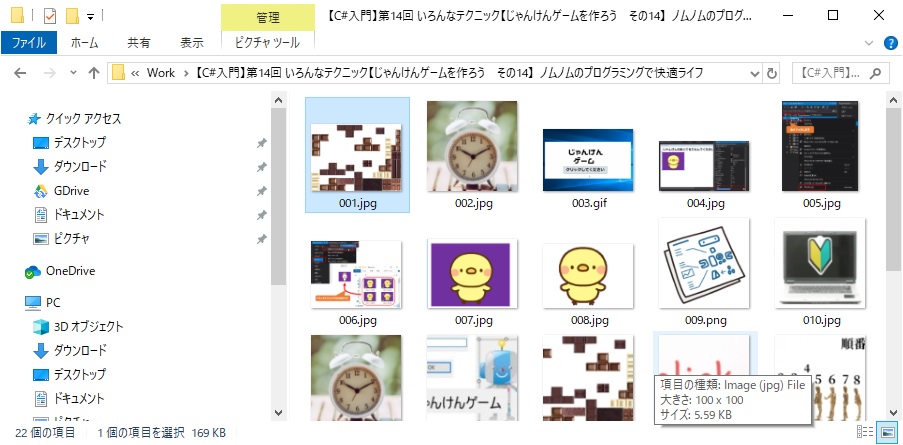
今回はこのサイトを使用しました。結果はこの通りです。
さっそくロジック公開!
以下に、ホームページ上の画像を一括取得するロジックです。
それでは解説していきます。
1.まずはHTMLを取得する
最初にホームページのソースであるHTMLを取得します。
//******************************************
// 1 HTMLを取得
//******************************************
System.Net.WebClient wc = new System.Net.WebClient();
//URLからストリームを読み込む
System.IO.Stream st = wc.OpenRead(url);
//エンコード
System.Text.Encoding enc = System.Text.Encoding.GetEncoding("UTF-8");
System.IO.StreamReader sr = new System.IO.StreamReader(st, enc);
//HTMLを取得
string html = sr.ReadToEnd();WebClientクラスを使ってHTMLを取得します。
次にHTMLの解析
それでは次にHTMLを解析し<img>タグを取得します。
といっても特別なことはしません。正規表現で取得します。
ソースの頭に
using System.Text.RegularExpressions;を追加してやりやすいようにします。
正規表現については以前記事にしていますので参考にして頂ければと思います。

//******************************************
// 2 タイトルを取得する
//******************************************
string title = Regex.Match(html, @"<title>(.*)</title>", RegexOptions.IgnoreCase).Groups[1].Value;
if (title.Trim() == "" )
{
MessageBox.Show("タイトルの取得に失敗しました。");
return false;
}
//******************************************
// 3 画像一覧よりURLを取得する
//******************************************
List<string> image_list = new List<string>();
foreach (Match match in Regex.Matches(html, @"<img.*src\s*=\s*" + "(\"|')" + @"(.*\.(jpg|jpeg|gif|png))" + "(\"|')\\s" + @".*>", RegexOptions.IgnoreCase))
{
image_list.Add(match.Groups[2].Value);
}
//******************************************
// 4 後処理
//******************************************
sr.Close();
st.Close();ちなみにこれではダメな場合があります。imgタグのsrc以外にも画像URLが紛れている場合イメージのURLの取得に失敗する場合があります。
できれば正規表現だけで行きたいところですが、できなければ他の対応策を考える必要があります。
- match.Groups[2].Valueの文字列をイメージURLになるように加工する
- HTMLを分割して 正規表現で検索をかける。例えばタグごとに分割するなど
- 正規表現でタグの属性をすべて持ってきて加工する
こんな感じでいろいろ考えてみてください。
最後にダウンロード
最後にリスト化したイメージのURLをファイル名を指定してダウンロードします。
private bool GetImagebyURL(string url, string referer , string fileName)
{
try
{
System.Net.HttpWebRequest webreq = (System.Net.WebRequest.Create(url) as System.Net.HttpWebRequest);
//Chrome バージョン28に偽装
webreq.UserAgent = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.63 Safari/537.36";
//リファラの設定
webreq.Referer = referer;
//サーバーからの応答を受信するためのWebResponseを取得
System.Net.HttpWebResponse webres = (webreq.GetResponse() as System.Net.HttpWebResponse);
//応答データを受信するためのStreamを取得
System.IO.Stream strm = webres.GetResponseStream();
//ファイルに書き込むためのFileStreamを作成
System.IO.FileStream fs = new System.IO.FileStream(fileName, System.IO.FileMode.Create, System.IO.FileAccess.Write);
//応答データをファイルに書き込む
Byte[] readData = new Byte[1023];
while (true)
{
//データを読み込む
int readSize = strm.Read(readData, 0, readData.Length);
if (readSize == 0)
{
//すべてのデータを読み込んだ時
break;
}
//読み込んだデータをファイルに書き込む
fs.Write(readData, 0, readSize);
}
//閉じる
fs.Close();
strm.Close();
}
catch(Exception ex)
{
MessageBox.Show(ex.Message);
return false;
}
return true;
}まとめ
最近、コンテンツの在り方に迷走しています。ただ説明するだけであればもっと大手サイトに行ったりすればわかりやすく大抵の情報は手に入ってしまいます。
ではこのサイトが他のサイトとの差異・・・。つまりオリジナリティを出すにはどうしたらよいのか、どういったコンテンツが今の訪問者にとって有益なのか、いろいろ挑戦していきたいと思っています。
ここまで読んで頂いてありがとうございます。